
On Tuesday, March 24, Google’s research team quietly posted a paper on its blog. By Thursday, it had erased tens of billions of dollars from some of the most popular stocks in the AI investing universe. If you own Micron, Samsung, SK Hynix, SanDisk, or any memory-chip-adjacent fund, you need to understand exactly what happened — and more importantly, whether this is a buying opportunity or a structural threat to your investment thesis.
What Is TurboQuant? (Explained Without a Computer Science Degree)
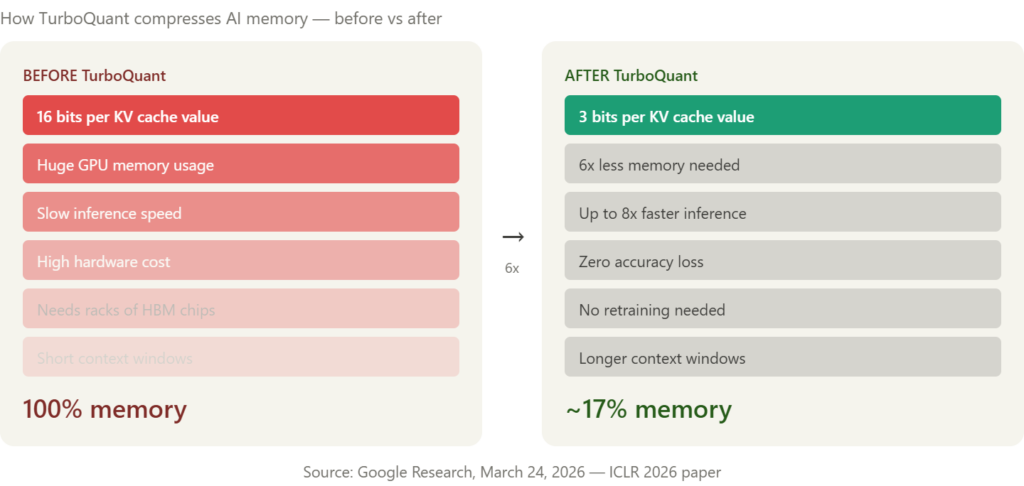
Every time an AI model like ChatGPT, Gemini, or Claude generates a response, it doesn’t start from scratch with every word. It stores its previous calculations in something called a KV cache — short for key-value cache. Think of it like the AI’s short-term memory: a scratchpad that lets it remember the context of a long conversation without re-processing everything from the beginning each time.
As models process longer inputs, this cache grows rapidly, consuming GPU memory that could otherwise be used to serve more users or run larger models. And because this cache has historically required high-bandwidth memory (HBM) chips running at full precision, it has been one of the primary reasons AI data centres need racks and racks of expensive memory chips.
TurboQuant compresses the cache to just 3 bits per value, down from the standard 16, reducing its memory footprint by at least six times without any measurable loss in accuracy — and crucially, without requiring training or fine-tuning of the underlying model.
The result is a 6x reduction in memory consumption and up to 8x faster inference throughput on Nvidia H100 GPUs. In plain terms: the same AI model that used to need six servers’ worth of memory can now run on one — and run eight times faster while doing it.
The paper was authored by Amir Zandieh, a research scientist at Google, and Vahab Mirrokni, a VP and Google Fellow, and it builds on two years of prior research from the same team. An official open-source release is expected in Q2 2026, timed around the paper’s formal presentation at ICLR 2026 in late April.
The Market Reaction Was Immediate and Brutal
The investing community drew one very clear conclusion: if AI needs 6x less memory, memory chip companies have a problem.
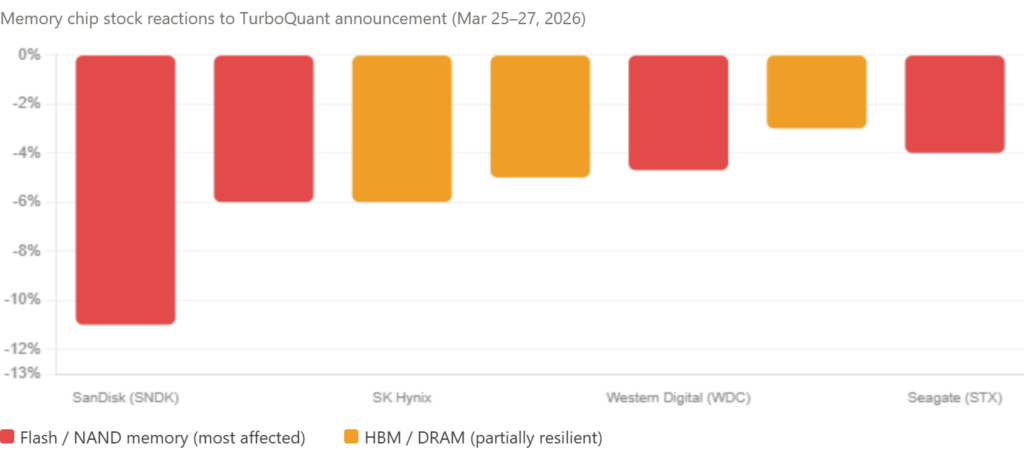
SanDisk fell 5.7%, Micron dropped 3%, Western Digital declined 4.7%, and Seagate slid 4% in the first US trading session after the announcement. Then the selling continued. In the days that followed, Micron, Western Digital, and SanDisk all slid at least 7% in total US trading.
In South Korea, SK Hynix and Samsung fell 6% and nearly 5% respectively. Japanese flash memory company Kioxia dropped nearly 6%. TheStreet
Micron has fallen in each of the past six sessions — tumbling over 20% in total, its worst multi-session performance since the April 2025 tariff shock selloff. That’s a company that was up 34% year-to-date just weeks ago, now surrendering most of those gains in less than a week.
The comparisons to DeepSeek — the Chinese AI model that briefly crashed Nvidia in January 2025 — were immediate. Comparisons quickly emerged between this development and the industry-wide shockwaves caused by DeepSeek last year. The fear is the same: a software efficiency leap makes the hardware buildout look overbuilt.
Is This the New DeepSeek Moment for Memory Stocks?
The DeepSeek comparison is seductive but imprecise. Here’s why TurboQuant is both more and less alarming than investors may think.
Why it’s more targeted than DeepSeek: DeepSeek threatened the entire AI hardware supply chain — GPUs, networking, data centres, the works. TurboQuant is laser-focused on one specific component: memory used during AI inference. The algorithm offers no relief for the massive RAM needed for AI model training, as it strictly compresses data during the inference stage. Training — which is where the biggest single pools of HBM memory are deployed — is completely unaffected.
A new split is now visible in the AI memory trade: shares of Samsung and SK Hynix — makers of high-bandwidth memory used in Nvidia AI accelerators — recovered most of their declines by Friday. Meanwhile, losses extended for makers of flash memory including Kioxia, which had soared in recent months. The market is already beginning to draw the correct distinction: HBM for training = still needed; NAND/flash for inference caching = at risk.
Why the bear case may be overstated: Wells Fargo invoked Jevons Paradox in its investor note — the idea that making AI more efficient lowers costs, which can actually drive much wider use and demand over time. Yahoo Finance The logic is compelling: if running a frontier AI model costs 6x less memory, more companies will deploy those models, more inference will happen, and total memory demand could actually rise even if memory-per-workload falls.
One analyst at Citrini Research put it bluntly: “It’s like saying Aramco should crash because Toyota came out with a next-generation hybrid engine.”
Morgan Stanley’s semiconductor analyst Shawn Kim called the stock reaction excessive and argued that TurboQuant could ultimately benefit memory makers over the longer term.
What Hasn’t Changed — And Why It Matters
Before you make any portfolio moves, it’s worth being clear on what TurboQuant does not do.
The compression tool currently lacks widespread deployment and exists purely as a laboratory development. CommunityAmerica Credit Union It will be formally presented at ICLR 2026 in late April. It has not been deployed at production scale across any major AI infrastructure stack.
Analysts at Quilter Cheviot described TurboQuant as “evolutionary, not revolutionary,” noting that it does not alter the industry’s long-term demand picture.
Memory chip companies had been riding a multi-year upcycle fuelled almost entirely by AI infrastructure buildout — TurboQuant introduces a credible question mark over how long that cycle continues. But AI infrastructure spending is growing at extraordinary rates, with Meta alone committing up to $27 billion in a recent deal with Nebius for dedicated compute capacity, and Google, Microsoft, and Amazon collectively planning hundreds of billions in capital expenditure on data centres through 2026.
A technology that reduces memory requirements by six times does not reduce spending by six times, because memory is only one component of a data centre.

What Should AI Investors Actually Do?
Here is a practical, clear-eyed framework for navigating this moment:
1. Don’t panic-sell Micron at the bottom of a 20% drawdown. One analyst reiterated a $700 price target on Micron and said he would be a buyer into the pullback, seeing little reason to revise fiscal year 2028 estimates. Retail traders on Stocktwits are largely unfazed, with one user pointing to the stock’s sharp rebound from a similar dip in December 2025. If your original thesis was based on AI training demand — which is unaffected by TurboQuant — that thesis hasn’t changed.
2. Reassess flash memory vs HBM exposure. This is the most important distinction TurboQuant creates. HBM makers like SK Hynix and Samsung recovered most of their losses quickly 24/7 Wall St. because the market correctly identified that HBM for training is not threatened. Flash memory and NAND — more directly exposed to inference caching — face a more legitimate question mark. Review your positions accordingly.
3. Add or hold Nvidia. Nvidia is counterintuitively a winner under TurboQuant — GPUs do not become less necessary when memory efficiency improves. They become more efficient per dollar, potentially accelerating GPU adoption in use cases that were previously cost-prohibitive. TurboQuant makes every H100 and Blackwell chip more valuable, not less.
4. Watch the ICLR 2026 presentation in late April. This is your next signal event. If Google’s formal presentation at ICLR shows real-world production adoption plans, the pressure on memory stocks could resume. If the academic community raises concerns about real-world accuracy or deployment complexity, expect a relief rally in memory names.
5. Think in years, not days. Long term, the trajectory points toward AI infrastructure becoming increasingly software-defined. Hardware will remain essential, but the margin opportunities and competitive moats will increasingly be built in algorithms, not in chip counts. This is the real long-term takeaway for AI investors — the edge is moving up the stack.
Key Takeaways
- Google unveiled TurboQuant on March 24 — a compression algorithm that reduces AI model memory requirements by 6x and delivers up to 8x faster inference on Nvidia H100 GPUs
- Micron has fallen over 20% in six sessions — its worst multi-day drop since the April 2025 tariff shock
- A clear split has emerged: HBM/DRAM makers (SK Hynix, Samsung) are more resilient; flash/NAND makers (Kioxia, SanDisk) are more exposed 24/7 Wall St.
- TurboQuant only affects inference memory — AI model training demand is completely unaffected
- Wells Fargo’s Jevons Paradox argument is compelling — lower memory costs may accelerate AI adoption and paradoxically increase total demand
- Open-source release expected Q2 2026; formal academic presentation at ICLR in late April — that’s your next major signal event CNBC
- Nvidia is a winner, not a loser — TurboQuant makes its GPUs more cost-effective per dollar of output
Frequently Asked Questions
Q: Should I sell Micron after a 20% drop? That depends on why you owned it. If your thesis was pure AI inference memory demand, TurboQuant is a legitimate headwind worth monitoring. If your thesis was broader — AI training, data centre buildout, the memory supercycle — TurboQuant doesn’t change that picture materially. Selling after a 20% drop is rarely the right move; reassessing your thesis is.
Q: Is this exactly like DeepSeek? Similar in structure — a software efficiency breakthrough threatening hardware demand — but more targeted. DeepSeek threatened the entire AI hardware stack. TurboQuant threatens only inference-stage memory, and only once broadly adopted. The knee-jerk selloff in HBM makers was arguably an overreaction, as the market itself recognised by Friday when those stocks partially recovered.
Q: Does TurboQuant hurt Nvidia? No — it helps Nvidia. TurboQuant delivers its 8x inference speedup specifically on Nvidia’s H100 GPUs. More efficient GPUs justify more GPU purchases. Nvidia is one of the clearest winners from this announcement.
Q: When will TurboQuant actually be deployed in production? An open-source release is expected in Q2 2026, likely timed around the paper’s formal presentation at ICLR 2026 in late April. Real-world production deployment at major AI labs will likely follow over the subsequent 6–18 months. This is not an overnight disruption — it’s a multi-year transition.
Q: Which ETFs are most exposed to this risk? ETFs with heavy memory chip concentration include SOXX (iShares Semiconductor ETF), SMH (VanEck Semiconductor ETF), and SOXS (3x inverse semiconductor). If you hold broad semiconductor ETFs, your exposure to memory names is real but diluted by Nvidia, TSMC, Broadcom, and other less-affected names.
⚠️ Disclaimer: This article is for informational and educational purposes only and does not constitute financial advice. All investment decisions carry risk. WealthNerve recommends consulting a qualified financial advisor before making investment decisions. Past performance is not indicative of future results.